
生成相关
生成相关
Audiogen
ICLR 2023
Meta AI
包括两个主要的阶段
第一阶段将原始音频编码成离散的token序列,通过一个压缩模型进行
该模型以端到端的方式进行训练,使用压缩表示重建输入音频,并以一组鉴别器的形式添加感知损失。
第二阶段使用一个自回归的Transformer-decoder language-model,在文本条件的基础上重建音频序列
主要贡献:
- sota方法
- 提高TTA生成性能的两个方法:classifier free guidance,动态文本和音频混合来提高组合性
- 可以做条件和非条件的音频延续
- 探索了音频保真度和采样时间之间的关系
Method

Audio representation
一个时长为d的音频信号可以表示为一个序列 $x\in[-1,1]^{C_a \times T}$ ,$C_a$ 是通道数,$T=d\cdot f_{sr}$ 是采样点数,至于为什么是 $[-1,1]$ ,是因为py库读取wav文件会自动归一化
Audio representation model 包含三个部分
- encoder network E:将音频片段作为输入,输出一个latent representation $z$
- quantization layer Q:使用Vector Quantizaiton将 $z$ 压缩为 $z_q$
- decoder net work G:从压缩表示 $z_q$ 中重建时域信号 $\hat x$
整个系统端到端进行训练,损失包括时域和频域上的重建损失,以及不同时间分辨率的感知损失,这一部分通过多个鉴别器来实现。
训练目标:
时域重建损失:$\ell_t(x,\hat x)=\Vert x-\hat x\Vert_1$
频域重建损失:
其中 $S_i$ 是根据 $i$ 改变的不同窗长和步长的64-bins梅尔谱图,系数 $\alpha_i$ 用于平衡两项损失,但是这里设置的是1
感知损失:
使用一个multi-scale STFT-based discriminator来捕获声音信号中的不同结构。
判别器的结构是一样的,但是时间分辨率不同,对抗损失如下
根据公式,这个 $D_k(\hat x)$ 输出的应该是为真实样本的概率
还有特征匹配损失(这个在VITS中也出现了),L是判别器的层数
判别器的总损失还加了一个部分,总的如下
对抗损失的两部分,对真样本 $x$ 输出要大,假的输出要小,因为是损失,所以二者都取负,得到的就是上面这种形式。
Audio language modeling
看不懂,什么卵
给定一个文本输入 $C$ ,Audio Language Model(ALM)组件输出一个音频token序列 $\hat z_q$ 然后在其上面做音频重建
给定如下:
一个文本编码器F,将原始文本输出投射成一个语义稠密表示(semantic dense representation)$F(c)=u$
一个查阅表(Look-Up-Table, LUT)将音频token $\hat z_q$ 嵌入一个连续的空间,$LUT(\hat z_q)=v$
然后将 $u,v$ 连接,得到 $Z=u_1,\dots,u_{T_u},v_1,\dots,v_{T_v}$
然后使用上面这个表示 $Z$ ,训练一个Transformer-decoder language-model,使用如下损失函数
两个连乘,N是样本数吗?然后下标是音频嵌入连续空间序列
突然懂了
首先这是一个Transformer序列预测器,目标是给定文本,得到音频token序列,上面损失函数是一个条件熵的形式,对于一条样本,最开始的条件是文本表示 $u$ ,然后依次预测下一个音频token,每次预测计算一次条件熵。
长序列预测问题
本方法对原始音频下采样32倍,让每个audiotoken关联2ms,这会导致很长的序列,因为每秒就需要500个token。
使用Multi-stream audio inputs的方法缓解这个问题
看不懂,看代码的时候再研究研究
Experiments
一些评估指标
Frechet Audio Distance:FAD,是一种与人类感知密切相关的无参考评估指标
还评估了KL散度和主观的标准
做了音频续写的实验,使用的条件包括音频片段,音频相关文本,音频无关文本
Limitations
缺乏理解时间顺序的能力,经常生成莫名其妙的语音
Diffsound
TASLP2023
北大, Tencent AI lab
Dongchao Yang, Jianwei Yu
传统的自回归token解码器,有两个问题
- 梅尔谱token总是按顺序预测,这会限制模型的生成能力,因为有些声音的事件位置可能来自文本的两端
- 预测阶段,来自之前的错误的预测token会导致累计的预测错误
主要贡献: - 第一次在音频生成任务中使用Diffusion
- 提出了一种基于掩码的文本生成策略(mask-based text generation strategy, MBTG),有助于在AudioSet数据集上构建大规模文本-音频数据集
- 提出了三个客观的评价指标
Proposed text-to-sound framework
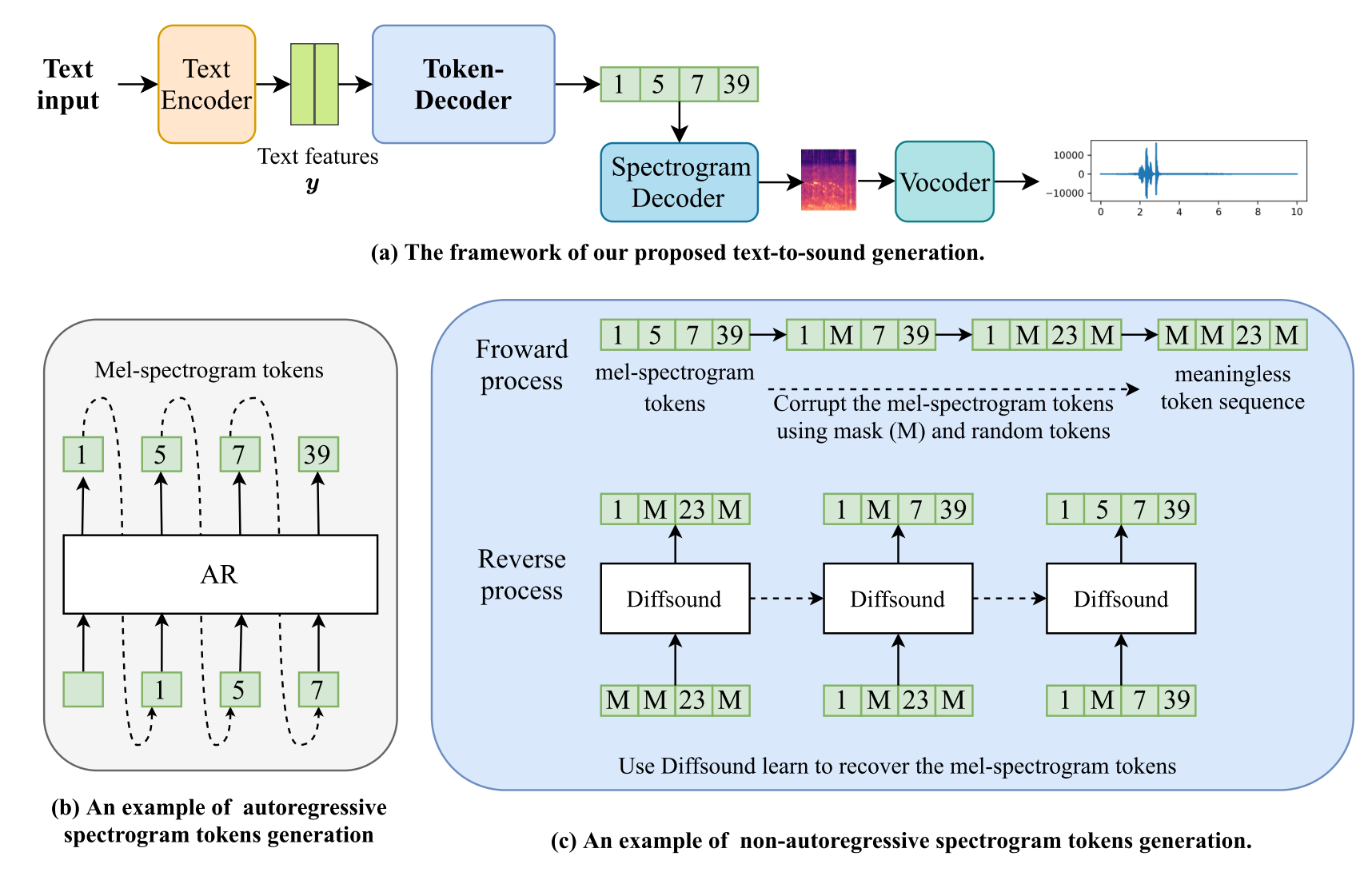
Text Encoder
有点搞,用的是BERT和CLIP的text encoder,但是效果更好,说明和图片的对比学习会让textencoder携带更多的语义信息
Learning Discrete Latent Space of Mel-Spectrograms via VQ-VAE
和TTS任务不同,TTA任务生成的音频与文本没有直接的对应关系
使用VQ-VAE来生成梅尔谱,问题就被转换成生成token序列
这里就是普通的VQ-VAE,不再详细记录
Token-Decoder
用于将文本特征变换到离散的梅尔谱图token序列,本文首先提出采用自回归的token-decoder
啥意思,前面说不用自回归,这里又用的自回归
说后面给了一个不同自回归的方法,等下看看
这里是用自回归预测前面VQ-VAE的encoder生成的梅尔token序列
在训练的时候,因为累计错误问题,使用"teacher-forcing" strategy,使用ground truth作为预测第 $i$ 个token时前 $i-1$ 个token条件
Vocoder
用的MelGAN,不懂
这还是自己训练的,在AS上训练的Diffusion-based decoder
就是经典Diffusion,参考AudioLDM中关于Diffusion的部分
这里给了一个好高大上的loss,叫负对数似然变分上界(variational upper bound on the negative log-likelihood)这一大坨狗屎是什么
首先,$q$ 是前向过程的分布,是加噪过程,$p$ 是不变的高斯分布,$p_\theta$ 是反向过程去噪的分布
第一个KL散度是加噪过程的损失,第二个是T步去噪过程的损失,这下懂了
Discrete Diffuison Model
因为送入Decoder的是离散的整数,不能在这上面加噪声,引入一个转移概率矩阵,用于知道前向过程中 $\boldsymbol{x}_0$ 如何一步一步转换为 $\boldsymbol{x}_t$
定义为:
对整个序列的前向过程可以写为:
其中 $\boldsymbol{c}(\cdot)$ 是一个将标量元素转换成one-hot向量的函数
沟槽的后面好多,这里暂时解释不清,继续往后看
然后说按照马尔可夫链和贝叶斯公式,可以计算出 $q(x_t|x_0)$ 和 $q(x_{t-1}|x_t,x_0)$
Non-Autoregressive Mel-Spectrograms Generation via Diffsound
作者希望预测的结果可以同时获得,并利用扩散模型T步的迭代优化预测结果
但是这里的特征是离散的,这里提到,离散扩散模型训练的关键是设计一种合适的策略来预定义马尔可夫转移矩阵 $Q_t$
注意到上面用的是离散标签在这搞扩散,我直接一个问号
这是将离散标签one-hot之后类似一个分类过程?
发现one-hot之后就是一个单位向量啊,然后左乘右乘就是选择 $Q_t$ 中的一个元素嘛
定义了三种转移矩阵
- Uniform transition matrix
- mask transition matrix
- mask and uniform transition matrix
这个就是传统diffusion的扩展,不想看了
Pre-Training Diffsound on AudioSet Dataset
对于文本描述,采用的做法是在标签两边随机插入一到两个mask标记,以使模型主要关注于声音事件而不是文本(感觉不太靠谱
采用渐进式训练,从单标签开始训练,然后再多标签实验
相比之前的文章,引入了一个Audio Caption Loss,是将生成的音频送入Audio caption模型,执行caption任务
Make an Audio
ICML2023
浙大,北大,字节跳动
Rongjie Huang, Jiawei Huang, Dongchao Yang
引入了一种数据增强方法,解决音频文本对数据稀缺的问题
使用频谱自编码器预测自监督音频表示而不是波形
支持多模态输入生成音频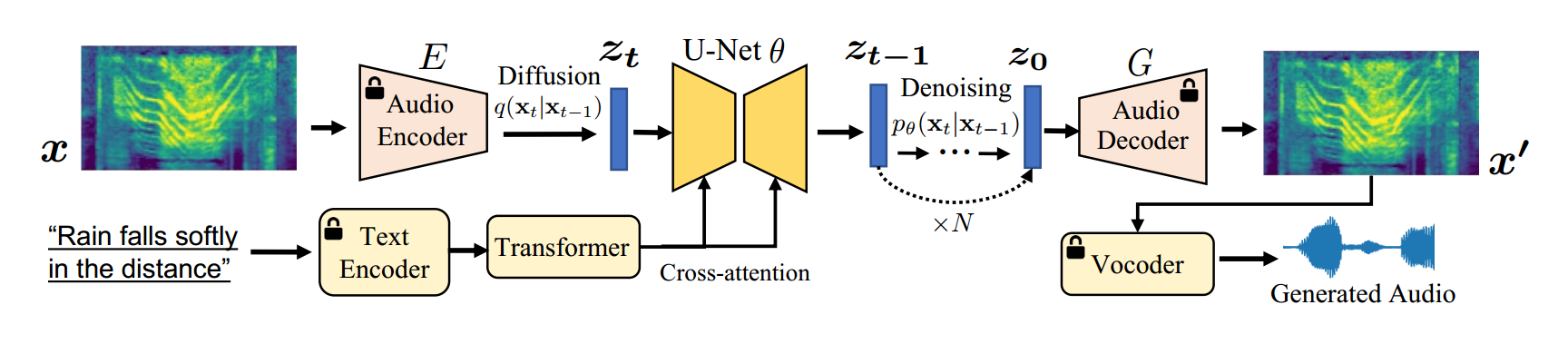
Pseudo Prompt Enhancement: Distill-then-Reprogram
这个方法包含两个阶段,一个expert distillation approach,使用audio caption方法,从无标签音频中得到文本描述,一个dynamic reprogramming procedure来构建不同的音频文本组合
Expert Distillation
使用两个预训练模型来做这个事情,分别是audio caption的工作和audio-text retrieval的工作,我记得两个都是DCASE的task
没看懂,这个audio-text retrieval的模型是拿来干嘛的?
Dynamic reprogramming
根据几个模板,把 $N\in \{0,1,2\}$ 个音频文本对使用预设的几个方法连接
Textual Representation
就说用了CLAP和T5-Large(一个大语言模型),实验表明二者的结果相近,但是CLAP更高效,因为不需要offline computation
Audio Representation
经典的梅尔自编码器带判别器提高重建质量
这个除了重建损失和对抗损失还有一个KL散度惩罚损失
后面还有经典的介绍Diffusion和CLassifier-Free Guidance
X-To-Audio: No Modality Left Behind
包括三个部分,text to audio, audio inpainting visual to audio(video or image)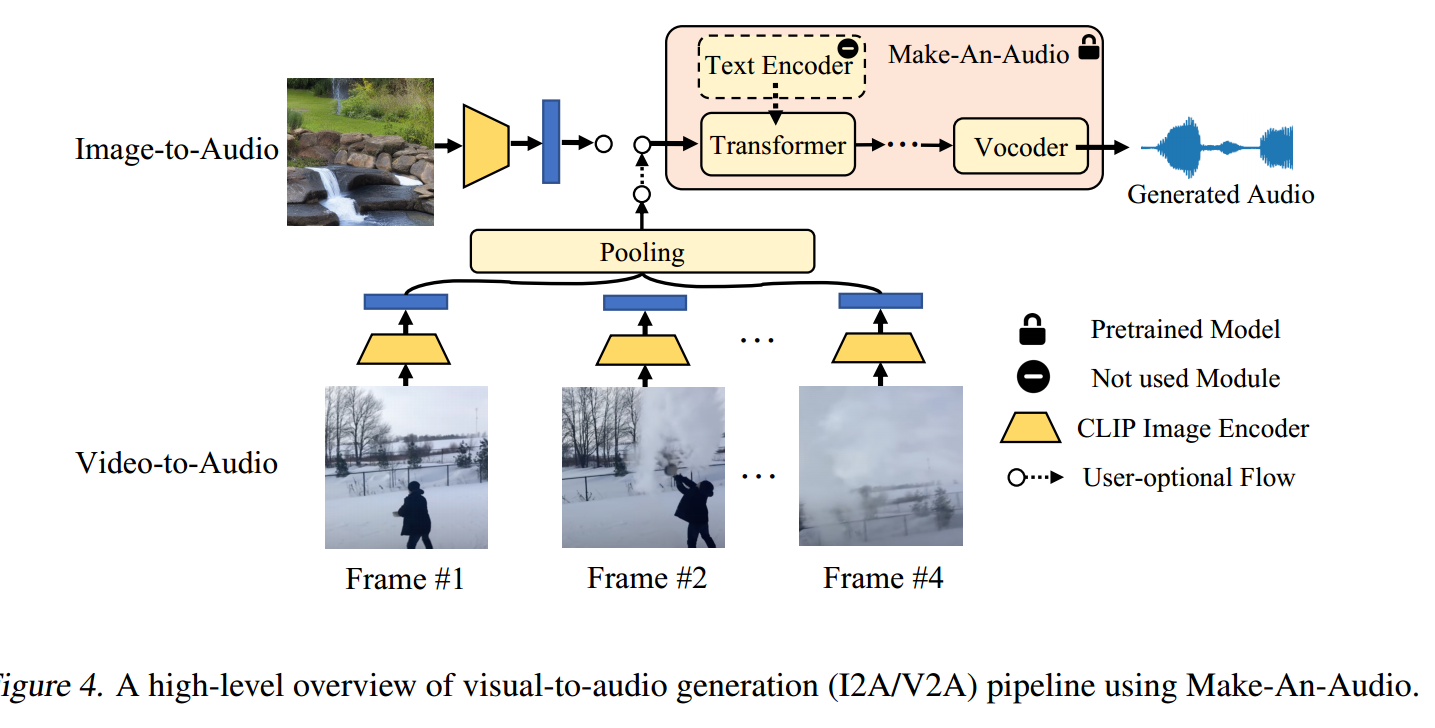
Personalized Text-To-Audio Generation
没搞懂他想干嘛
这里给了个例子,在给定打雷的声音时,让模型生成babycrying的音频,就会生成a baby crying in the thunder day
大概就是通过文本描述修改音频,添加背景声,或者插入说话的主体之类的
做法是对给定的音频片段,选取一个特定的时间段$t_0$然后对其进行Diffuision的加噪去噪过程
这里提到音频的文本对其度和真实度之间随着T的变大有一个trade-off
Audio Inpainting
通过mask来实现Inpainting的训练,采用了两种mask方法
一个是LaMa中的什么polygonal chains和任意宽高比的矩形mask(听起来像是在mel谱上做mask,因为原来的工作是图像上的
大概长这样
另一个是在语音相关文献中常用的帧级掩蔽策略
Visual-To-Audio Generation
用CLIP来抽取图像特征,用文本表示来弥合视觉和音频世界之间的模态差距,用一个或多个Flow模型将CLIP的特征向量空间映射到CLAP的特征向量空间
对于视频,抽取固定的4帧,池化得到4帧的平均表示,退化为图片转音频
Training and Evaluation
笑死用了18块V100
在常用的评估方法FID和KL散度之上,添加了CLAP分数来评估audio-text alignment
对比了Diffsound,AudioLDM和AudioGen
IS: inception score,在AudioLDM中,对他的解释是
IS is effective in evaluating both sample quality and diversity.
网上找的都说什么是用谷歌一个分类模型计算的,对于音频,需要专门的分类器 $C$
可以自己训练,计算公式如下
在AudioLDM中有讲,是用的PANNs分类器做的评估
消融实验中提到,对于文本特征提取,CLAP和T5表现差不多,但是CLAP性能高
与AudioLDM2的对比
二者同为多模态内容生成音频的工作,从结构、特征工程、结果三个角度来看
结构
AudioLDM2
- 使用AudioMAE编码音频特征
- 使用GPT-2生成其他模态特征
- 使用含Transformer块的U-net
Make-an-Audio - 使用自己训练的梅尔自编码器结构网络编码音频特征
- 使用CLIP和CLAP编码其他模态特征
- 使用的普通的卷积U-net
特征工程
AudioLDM2
- 使用各模态的专家模型抽取模态特征
- 使用GPT2生成音频大一统特征
Make-an-Audio - 也是用的专家模型抽取模态特征
- 使用Flow映射分布到自编码器特征空间
结果
AudioLDM使用的训练数据少很多,主观评价相对也更好
OVL:Overall quality
REL:relevance t the input text
Retrieval-Augmented text to audio generation
ICASSP 2024
University of Surrey
Yi Yuan, Haohe Liu
提出的问题:由于TTA模型训练数据的类别不平衡问题,其生成性能存在偏差,这些模型可以为常见的声音事件生成真实的音频片段,但是当遇到不太频繁或看不见的声音事件时,他们可能会生成不正确或不相关的音频。