
ICME2024介绍
ICME2024介绍
题目:在域转移下的半监督声学场景分类( Semi-Supervised Acoustic Scene Classification Under Domain Shift)
Introduction
声学场景分类(ASC):在环境中的预定义类中识别一个声学场景,比如广场,街道,餐厅
在ASC的深度学习方法的发展中产生了两个关键的考虑
- domain shift
- 标记数据的稀缺
比赛建议大家从半监督学习入手
数据集
Chinese Acoustic Scene(CAS) 2023 dataset
超过130小时,使用三个工业级的录音设备,从中国22个城市采集的10个不同的声学场景
每个声音片段为10s,有位置和时间戳等元数据
采集时间为2023年四月到九月
训练集有24小时,来自8个城市,有20%的带标签数据
测试集从12个城市中选择,有5个未见城市用于评估域转移
Baseline
pipeline如下
基线模型架构
包括两个SE块,一个Transformer encoder
SE block: 两个卷积层,通道数相同,kernel3x3
两个块的通道分别为64和128
每个块后面都有一个平均池化层,kernel2x2
Transformer:number of head 8,layers 1,全连接层单元数32
沿着时间框架的最大聚合以及一个完全连接的层被应用于获得输出
实验设置
使用 log mel作为输入特征
- 重采样到44100HZ
- 40ms汉宁窗,20ms步长,60Mel-filter bands
- logmel 大小为500x64
- fine-tune阶段使用Adam优化器,0.001 learning rate 32batch size
评估
使用各类准确率的平均值计算
其中N是类别数
baseline源论文中用的损失是分类交叉熵
baseline中使用的数据增强方法FMix
- 随机采样复数矩阵 $\boldsymbol{Z}\in\mathbb{C}^{T\times F}$ 和输入的梅尔谱图 $\boldsymbol{X}$ 形状相同
- 对 $\boldsymbol{Z}$ 使用低通滤波器
- 对 $\boldsymbol{Z}$ 的复数部分使用反向傅里叶变换❓,取实部得到灰度图
- 对灰度图的top n元素置1,其余置0,得到一个01mask

半监督学习方法
参考文献:知乎
伪标签(Pseudo-Label)

感觉就是用有标签数据训练模型,然后去预测无标签数据,然后用无标签数据的预测标签继续训练,在此技术上加上一个时变参数控制伪标签数据对模型的影响
不足:Pseudo-Label 方法只在训练时间这个维度上,采用了退火思想,即采用时变系数α(t)。而在伪标签这个维度,对于模型给予的预测标签一视同仁,这种方法在实际中存在明显问题。很显然,如果模型对于一个样本所预测的几个类别都具有相似的低概率值,如共有十个类别,每个类别的预测概率值都接近 0.1,那么再以最大概率值对应的类别作为伪标签,是不合适的,将会引入很大的错误信号。
Γ Model:Semi-supervised learning with ladder networks
思路:为了结局有监督和无监督之间的冲突,无监督学习希望尽可能保留原始信息,监督学习则主要保留和监督任务相关的信息。
网络结构
对于有标签数据,流经Encoder后通过顶层输出构造和原数据标签的目标函数
对于无标签数据,数据经过Encoder后经过Decoder逐层解码,并获得一系列的隐层表示,然后同右侧的无噪前向网络计算均方误差,这里每一层的隐层表示就是保证无监督学习对源数据全部信息的学习。
Π Model & Temporal ensembling Model:Temporal ensembling for semi-supervised learning

感觉思想也很简单,首先对于每个数据 $x_i$ ,做两次前向运算,一次前向运算包括两个步骤,随机增强变换和带Dropout的模型前向运算,引入的随机性会让两次计算的输出不同,接下来分情况
- 如果是带标签数据,则对于两个输出,算两次,第一次随便取一个输出和标签做交叉熵,第二次两个输出之间算均方误差
- 如果是无标签数据,计算两个输出之间的均方误差
对于 Temporal ensembling Model,其整体框架与 Π Model 类似,在获取无标签数据的信息上采用了相同的思想,唯一的不同是:
- 在目标函数的无监督一项中, Π Model 是两次前向计算结果的均方差。而在 temporal ensembling 模型中,采用的是当前模型预测结果与历史预测结果的平均值做均方差计算。
VAT:Virtual Adversarial Training: a Regularization Method for Supervised and Semi-supervised Learning
思路:模型所描述的系统应该是光滑的,因此当输入数据发生微小变化时,模型的输出也应是微小变化,进而其预测的标签也近似不变。
根据这个思路,引入对抗噪声的概念,优化目标包括三个部分
- 有标签数据的交叉熵
- 无标签数据的一致正则项

其中 $r_{adv}$ 代表对输入数据所施加的对抗噪声,$D$ 是模型对于施加噪声前后两个输入对应输出的非负度量(比如MSE或KL散度) - 熵最小化

结果:VAT 所用到的 一致性正则 和 最小熵正则 对于从无标签数据中挖掘信息提升模型泛化能力,都有显著的作用。
Mean Teacher:Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results

MixMatch: A Holistic Approach to Semi-Supervised Learning

优化目标还是两项,有标签数据的交叉熵,无标签数据和伪标签之间的均方误差
然后中间套用了不同的数据增强方法还有最后的概率锐化
看不太懂,要用的时候看知乎
Unsupervised Data Augmentation for Consistency Training

几乎完全一样的框架,重点在数据增强
- 采用了最先进的数据增强技术,在CV上运用了19年刚被提出来的 RandAugment,在NLP上则综合运用了 Back Translation 和 非核心词替换。这些技术可以保证无标签数据在语义不变的情况下,极大地丰富数据的表现形式。这使得 Consistency Regulation 可以从无标签数据中更有效地捕捉到数据的内在表示,这一点是早前如 Π Model 所无法实现的。
- 采用了最新的迁移学习模型。在文本分类任务上,研究人员采用 BERT-large 作为基础模型进行微调,由于 BERT 已经在海量数据上进行了预训练,本身在下游任务上就只需要少量数据,再与 UDA 合力,因而可以在 20条有标签数据上实现 SOTA 的表现。
- 采用了一系列精心设计的训练技巧。这包括平衡控制有监督信号和无监督信号的 TSA 技术,基于 Entropy Regularization 的锐化技术,无标签数据的二次筛选 等等。这些技巧或许是打败同年出生的 MixMatch 的主要原因。
看完之后我的总结
一致性原则+熵最小化原则
工作准备
数据集
- [x] ASC development dataset
- [ ] TAU UAS 2020 Mobile development dataset
- [ ] CochlScene dataset
模型
BEATS
这是去年看到的一个SED任务的SoTA方法,有无标签数据预训练的部分和有标签数据微调部分
Iterative Audio Pre-training
Dcase以前的方法
Task4
SubtaskA: The goal of the task is to evaluate systems for the detection of sound events using real data either weakly labeled or unlabeled and simulated data that is strongly labeled (with time stamps).
SubtaskB: The goal of this task is to evaluate systems for the detection of sound events that use softly labeled data for training in addition to other types of data such as weakly labeled, unlabeled or strongly labeled. The main focus of this subtask is to investigate whether using soft labels brings any improvement in performance.
Minjun Chen等人
对于子任务A,主要关注使用预训练模型,通过self-training的方式,训练多个不同架构的模型,然后做一个ensemble。(但是规则里说不能用model ensemble)
子任务A的三个模型
- SK-FD-CRNN
- FT-BEATs
- FT-BEATs-AST
对子任务B
- 为了平衡不同类别数据量之间的差异,对数据量小的类别做数据增强
Proposed Method
特征
对于SubtaskA,128mel-bins, 256 hop-length, 2048 windows-length
对于SubtaskB,巴拉巴拉
迭代自训练策略
- 使用所有SESED数据集的数据和AS的强标签数据训练三个架构的模型
- ensemble这些模型,为弱标签和没标签的数据生成伪标签
- 在生成伪标签的过程中,使用
class-wise fine-tuned thresholds and median filter length - 伪标签子集被用来迭代地训练或者微调模型
模型
taskA的三个模型
SK-FD-CRNN: 使用frequency dynamic convolution(FDY-CRNN)和selective kernel attention(SKA)来替换正常的7层CNN网络中的卷积,并且融合BEATs提取的特征。融合方法为(pool1d and interpolate)
FT-BEATs: 在BEATs的后面接了一个四层的Bi-GRU和一个线性层作为输出,使用较小的学习率训练所有参数
FT-BEATs-AST: 看描述是AST预训练模型和BEATs是平行的,然后二者的输出由一个平均池化层融合,学习率为0.0001
训练上面三个模型的时候都使用了mean-teacher半监督学习框架
taskB的模型如下
没懂,图里和描述不一样
描述说用一个decoder将AST提取的embeddings转换为逐帧的输出,就是图里上面那个框
两部分,一个是双向门限循环单元(biGRU),和一个线性层
数据增强
就是为了解决class-wise这个问题,然后发现mix-up方法效果最好,具体怎么mix的也没说
还有一种方法是oversampling
后处理
对不同的声音事件使用不同的中值滤波器窗长
使用一个tagging mask strategy来过来taskA中的strong predictions(❓)指logits高的吗
使用两组超参数,训练两组模型,第一组的训练目标是PSDS2分数,第二组是PSDS1分数(这都是什么指标
两组的时间分辨率也不一样,第一组39帧,第二组156帧(这个是指一个样本分的帧数吗?
实验
我看提交的全是ensemble的
Han Yin等人
只做taskB
- 首先,使用temporal Mixup做数据增强
- 提出了一个one-branch SED system和四个two-branch SED system能够使用软标签训练。
- 用一个注意力块加到two-branch中做信息融合
方法
Temporal Mixup
对于两个相同声学场景的不同样本,算加权和
对应软标签也一样算加权和
One-branch SED system
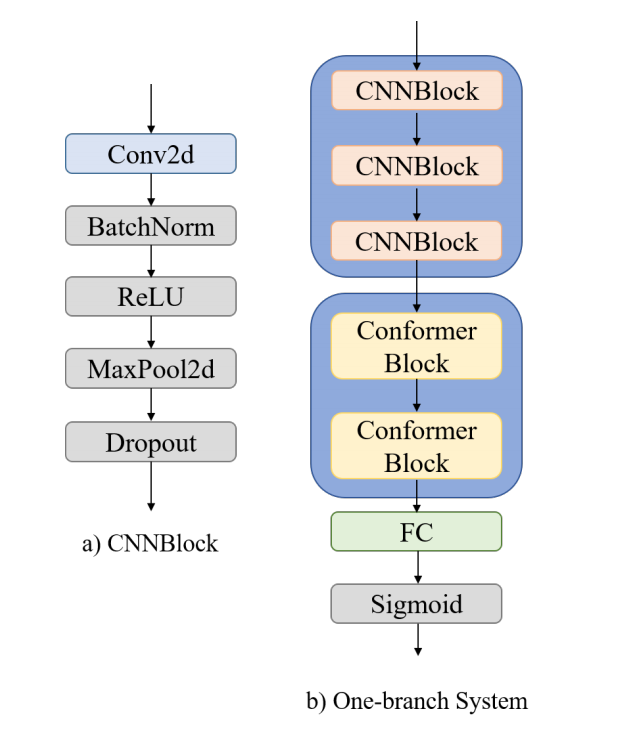
原来单支指的是一条路下来
这个Conformer block指路另一篇论文
Two-branch SED Systems
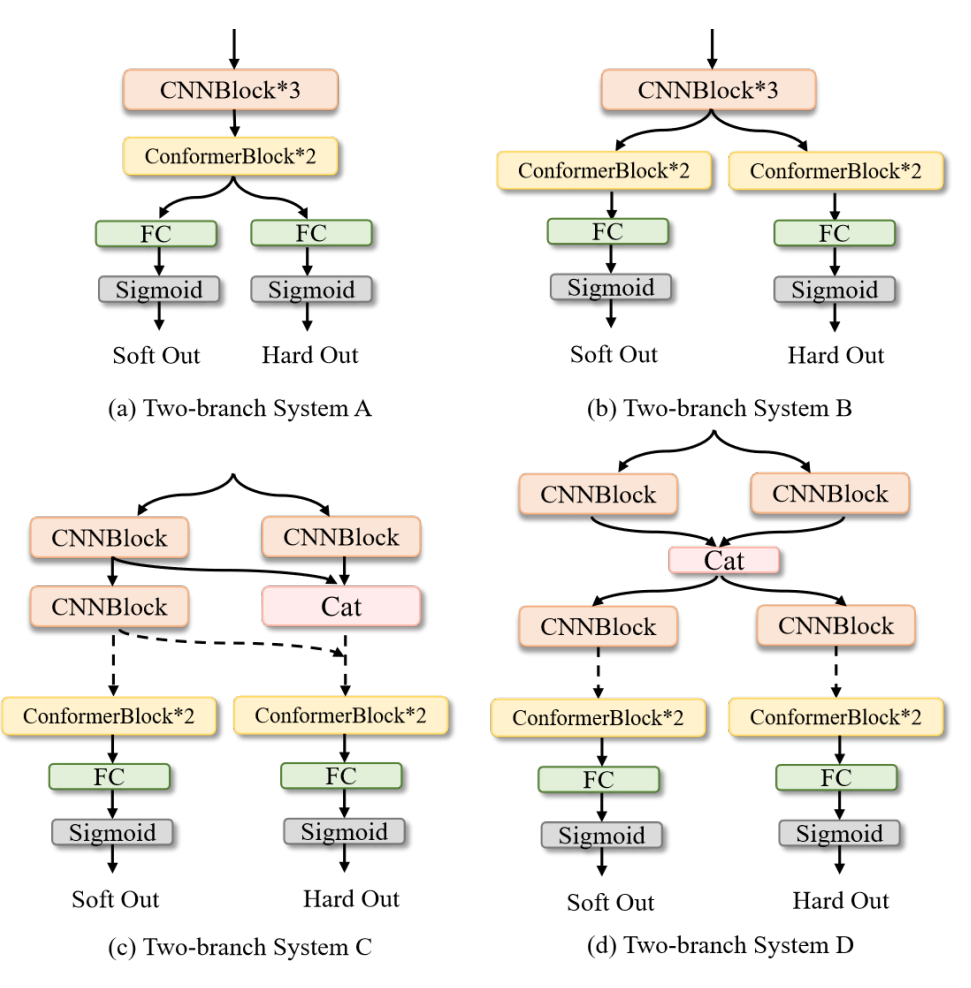
四种模式,最后对两个输出做不同维度(软硬度,事件维度,帧级维度)的注意力加权,加权系数是可学习的
实验
时域混合了这么多
训练参数:
梅尔:11025步长,22050窗长(500ms)
5折交叉验证
后处理
按照不同场景不太可能会出现的声音事件设计mask,引入先验知识
Xuenan Xu等人
指出了某些声音事件只会发生在某些场景中,所以在不同场景下训练不同的模型
主要探索将大规模数据集上通过自监督学习学到的知识转移到这个任务中
系统
预训练音频表示
对BEATs进行改良,首先在AS上训练,然后使用BEATs生成音频特征
考虑了两种预训练特征
Clip-level Pre-trained Features: 在整个序列上使用平均池化来获得Clip-level pre-traind feature。❓将全局特征与每个帧级的FBank特征连接起来,然后送入后续的网络
Frame-Level Pre-trained Features: BEATs模型生成的stride为20ms的特征被直接用于LSTM架构
SED Model
两种结构(怎么不给个图
CRNN: 将每层的Clip-level BEATs embeddings聚合得到一个单独的clip-levelembedding
然后将这个embedding和baseline的卷积块输出串联,使用GRU算概率
LSTM: 使用上面第二个帧级特征,每层的连接,然后送入LSTM
Task1
低复杂度ASC,但是ICME好像没有复杂度要求
Jiaxin Tan等人
利用Deep separable convolution将卷积分成几块,比传统卷积的参数和计算开销更小
最主要的就是把传统卷积换成了blueprint separable convolution
然后用知识蒸馏压缩模型
教师模型如下
学生模型如下
蒸馏方式是标准方式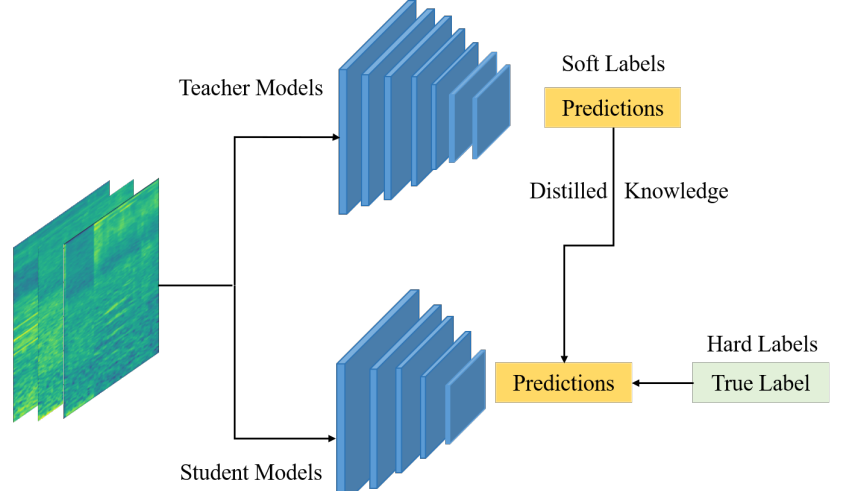
Yiqiang Cai等人
还是用的separable convolutional layers加知识蒸馏
在Residual Normalization layer中加入了一些可学习的参数,进一步提高了性能
通过引入用于数据增强的设备仿真提高设备域泛化能力(这个可以学习,对非分类要素进行特定方向的数据增强抹平分布差异)
采用不同的数据增强策略,解决过拟合问题
ICME的数据集都是用同一种设备采集的,故设备模拟好像没必要
使用两种数据增强方法:
Mixup:线性差值两个随机样本
Freq-MixStyle:对频带进行归一化
模型主要以时频分离卷积模块为基础
自适应残差归一化(Adaptive Residual Normalization)
用于保证训练过程中残差的数值稳定性?
频域实例标准化(frequency-instance normalization)
其中 $\rho,\gamma,\beta$ 都是可学习的参数,该处理被放在第一层卷积和每个TF-SepConv 块后
Loss包含两部分,学生模型的输出和标签ground truth之间的交叉熵,学生模型的输出和教师模型的输出之间软标签的KL散度
Schmid等人
才发现task1的模型大小限制为128kb
数据预处理,看不懂这写的啥
For all models, we randomly roll the waveform over time with a maximun shift of 125ms.
对于CP-Mobile和PaSST,还使用了最大大小为48Mel bin大小的频域掩蔽,并通过随机改变Mel滤波器组的最大频率来应用patch shifting。
shifted crops
TAS UAS2022和TAU20的数据集内容是一样的,但是前者把后者10s一段的样本分成了1s一段的样本,所以可以把他们重新拼成10s的片段
然后使用0.5s的步长循环移位切割10s音频段,作为数据增强
还说什么相比于随机1s片段,可以先计算教师模型的预测,然后离线做知识蒸馏,感觉没什么说法
Freq-MixStyle
对频谱图中的频段进行归一化处理,然后利用两个频谱图的混合频率统计量对其进行反归一化处理❓
然后是设备方面的增强(Device Impulse Response Augmentation)感觉没什么用就不看了
教师模型选的是PaSST和CP-ResNet的ensemble